Unlocking Hidden Potential: A Semantic Approach towards SFIA Competency Mapping in RDF
Matteo Casu
20 Dec 2024

Putting our SFIA RDF conversion into use: semantic use cases with SFIA, RDF graphs, vector search and LLMs
Motivations
I confess that the idea of codifying my competences (not to mention my career path!) would have terrified me back in the day. My journey through a degree in philosophy, my studies and research in computer science, and then my career in the industry, was not, at the time, to be considered orthodox. And yet I never had much doubt as to what was driving my interests and my passions: it was semantics. Semantics in all its forms, the idea that there are geometrical patterns of meaning and connections referring to a world (our world, or abstract worlds) behind words, behind formulas, behind documents, behind anything that humans express with signs of some sort.
From this point of view, the idea of identifying my strengths, the results of much effort, and helping me build a narrative of who I am professionally, seems less stressful. There is indeed a coherence! And this is true for any of us, really, impostor syndrome keeps too many people away from being more confident at what they have built without realising.
A formal description of my competences will never capture who I am, not even just professionally. But it is a tangible witness of what partial, imperfectly described, but existing abilities I have developed in some contexts.
In the same vein, we can imagine a job role, or a needed set of abilities we need for a project, and write it down using a competency framework.
Formulating a challenge (of any sort) as a set of competences can be a revealing exercise. Imperfect as it is, it might, if not solve the challenge, open up insights, and maybe answer different, related questions.
We can try to formalise questions and desiderata such as:
- “What would it take to do this project? What does this project really imply?”
- “Johanna would be perfect for doing this, but she’s busy.. I need a clone of Johanna!”
- “What is the gap between my current abilities and the challenge I want to be able to face?”
- “What is the gap between my current workforce and that project?”
- “Would Simon be happier on project X or Y?”
- “Would Simon make more of a difference on project X or Y?”
- “Would Simon learn more on project X or Y?”
As you can see, we are not cynically trying to optimise efficiency here, but rather to be more aware of what human and business consequences competences have.
In the following we would like to present some approaches and technologies that can help build solutions able to respond to these queries.
Use Cases, and Their Tech
We have seen in another article how we at Semantic Partners have ported SFIA to RDF (in one of the possible ways of doing it). I will sometimes use the RDF format of SFIA to present my examples, but the same techniques or ideas can be applied starting from other SFIA distributions, such as the spreadsheet one, even if possibly with some different intermediate steps required.
Let’s Try Some Queries!
Let us load our SFIA RDF dataset into a triple store, or in memory, using a library like rdflib (for Python) or rdf4j (for Java).
Let us use SPARQL to print a visualisation of the top-level categories, and how many skills are tagged with them or any of their sub-categories.
prefix categories: <https://rdf.sfia-online.org/9/categories/>
prefix sfia: <https://rdf.sfia-online.org/9/ontology/>
prefix skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?catLabel (count(distinct ?skill) as ?c)
WHERE {
?cat a sfia:Category;
skos:prefLabel ?catLabel.
?subcat skos:broader* ?cat.
filter not exists {?cat skos:broader ?supercat}.
?skill a sfia:Skill;
sfia:skillCategory ?subcat.
}
GROUP BY ?catLabel
ORDER BY desc(?c)This returns:
Development and implementation,41
Strategy and architecture,31
Delivery and operation,31
Change and transformation,16
Relationships and engagement,15
People and skills,13Let us see some data for skills. We will use this query to build a simple vector index later. Notice that we “clean” the notes of any new line character, just to simplify them.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX sfia: <https://rdf.sfia-online.org/9/ontology/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?code ?label ?description ?notes ?category
WHERE {
?skill a sfia:Skill;
skos:notation ?code;
rdfs:label ?label;
sfia:skillDescription ?description;
sfia:skillNotes ?rawNotes;
sfia:skillCategory/skos:prefLabel ?category.
bind(replace(str(?rawNotes),"\n"," ") AS ?notes)
}The result (a CSV of the first two rows, a bit abbreviated):
ACIN,Accessibility and inclusion,Driving accessibility and inclusion in services and products.,"Activities may include, but are not limited to [..]",Systems development
ADMN,Business administration,"Managing and performing administrative services and tasks to enable individuals, teams and organisations to succeed in their objectives.","The application of this skill varies widely depending on [..]",Stakeholder management
...We see that, associated with each skill, SFIA gives some useful descriptions.
Let’s Try Some Vector Search!
Suppose we need a search solution to find, among the about 150 SFIA skills, the most relevant to a given description we have. With a traditional keyword search an analyst could search for “programming” and find SFIA’s PROG skill, which has “Programming” in its very description. However, we would like to find PROG when we search for “developers”, which is a conceptually close concept, whether or not it is present in the PROG associated labels or descriptions. Moreover, we would like to give our search engine a short requirement (“developers expert in database configuration”), or an entire project description, and get a list of relevant skills. This is possible with vector search, which indexes documents to search (in our case, skills) and queries in an “embedding” mathematical space (based on an off-the-shelf language model).
There are many vector-search capabilities out there nowadays. There are specialised vector databases, and traditional search solutions which now incorporate vector search as a feature.
For this example, we will use a Python library, Superlinked, to create the index in memory, so that no database is required.
First, we use the above SPARQL query to create a CSV of skills, their labels, notes, and categories. Then, we index them and prepare them for our queries. This is an intermediate step we use for didactic purposes – in a real application, we could pass the results from the SPARQL query directly to the indexer.
The good thing of being able to query the SFIA dataset with a graph query language is that we can easily decide to only consider skills (or skill levels) falling under a certain criterion, by navigating the graph. Be it a category, or other type of link with a given SFIA subset.
A useful feature of Superlinked is the ability to give different weights to the various “fields” (columns) coming from the CSV. We can make the description “count” more than, say, the notes, in the final ranking.
##
## We define a pydantic-style schema reflecting our CSV
##
@schema
class SkillSchema:
code: IdField
label: String
notes: String
description: String
category: String
skill_schema = SkillSchema()
##
## We load the CSV
##
source: InMemorySource = InMemorySource(
skill_schema, parser=DataFrameParser(schema=skill_schema)
)
source.put(pandas.read_csv(skills_csv))
##
## We define the embeddings for each of the CSV fields, using a common language model
##
text_model = 'sentence-transformers/all-MiniLM-L6-v2'
label_space = TextSimilaritySpace(
text=skill_schema.label, model=text_model
)
notes_space = TextSimilaritySpace(
text=skill_schema.notes, model=text_model
)
desc_space = TextSimilaritySpace(
text=skill_schema.description, model=text_model
)
category_space = TextSimilaritySpace(
text=skill_schema.category, model=text_model
)
##
## We prepare the in-memory index and define a template for the queries
##
index = Index(spaces=[label_space, desc_space, notes_space, category_space])
query_text_param = Param("query_text")
simple_query = (
Query(
index,
weights={
label_space: Param("label_weight"),
desc_space: Param("description_weight"),
notes_space: Param("notes_weight"),
category_space: Param("category_weight"),
},
)
.find(skill_schema)
.similar(label_space.text, query_text_param)
.similar(desc_space.text, query_text_param)
.similar(notes_space.text, query_text_param)
.similar(category_space.text, query_text_param)
.limit(Param("limit"))
)
executor: InMemoryExecutor = InMemoryExecutor(
sources=[source],
indices=[index],
context_data={CONTEXT_COMMON: {CONTEXT_COMMON_NOW: now()}}
)
app = executor.run()
##
## This method will make a query, giving different weights to the various fields
##
def get_skills(text):
results = app.query(
simple_query,
query_text=text,
label_weight=2,
description_weight=10,
notes_weight=2,
category_weight=2,
limit=10,
)
return [result for result in results.entries]Now, we can run this code with a text as input (a phrase, or longer text), getting a list of relevant SFIA skills. We wrapped it in a simple UI:

This is a very simple way to help recommend / navigate / suggest the set of SFIA skills. In a real-world context, we would experiment by including (or not) the notes (which are quite long and may be noisy), and giving different weights to the various components (notes, description, labels…).
Let’s Ask an LLM to Guess the Levels
We will now demonstrate an application with an LLM.
Suppose we have found a skill that relates to a project description – for example DBAD (“Database Administration”) using the above approach. Now we want something that vector search cannot give us: we would like to know what level of that skill is required by that project. For this more subtle task we can employ an LLM – and then have a human validate the response.
Suppose the request is:
Developers expert in databases configuration. They should be able to configure a SQL database, deploy it at scale and configure security rules for it.
We can compose a prompt for an LLM by appending the descriptions for the skill levels for DBAD with a simple prompt command.
We are a HR consultancy, we need to find what skills match a given text.
You are given:
- SKILL: the description of a skill
- SKILL LEVELS: a list of increasing levels of competence for the skill (the codes follow the pattern <SKILL>_<LEVEL>)
- TEXT: a project summary, a person's CV, or other similar text
Identify the type of text.
Does this SKILL, in general, match the text? Is it relevant and required for it?
Tell me the skill levels' range in the list (for example, "3 to 6", or "2 to 5").
If yes, what is the minimum skill level necessary to have? Why?
Finally, print a json like the following:
{
"level_required": "ABC_3",
"skill_relevance": "60%"
}
Caution! Sometimes the skill is not relevant to the text.
** SKILL **
DBAD,Database administration: "Installing, configuring, monitoring, maintaining databases
and data stores, ensuring performance and security and adapting to evolving technologies."
** SKILL LEVELS **
DBAD_2: Assists in database support activities.
DBAD_3: Performs standard database maintenance and administration tasks. Uses database
management system software and tools to collect performance statistics.
DBAD_4: Develops and configures tools to enable automation of database administration tasks.
Monitors performance statistics and create reports. Identify and investigates complex problems
and issues and recommends corrective actions. Performs routine configuration, installation,
and reconfiguration of database and related products.
DBAD_5: Identifies, evaluates and manages the adoption of database administration tools and
processes, including automation. Develops and maintains procedures and documentation for
databases. Contributes to the setting of standards for definition, security and integrity of
database objects and ensures conformance to these standards. Manages database configuration
including installing and upgrading software and maintaining relevant documentation. Monitors
database activity and resource usage. Optimises database performance and plans for forecast
resource needs.
** TEXT **
developers expert in databases configuration.
They should be able to configure a SQL database, deploy it at scale and configure security
rules for it.Notice that here we used generic descriptions (the “essence” of each level) provided by SFIA. But SFIA 9 also provides attributes, that are detailed descriptions of each level along different axes: for example, Autonomy, Influence, Complexity, etc. If we were interested only in a particular Level attribute (say, Autonomy), we could insert that. We can get the Autonomy description for each level of DBAD with this query:
PREFIX skills: <https://rdf.sfia-online.org/9/skills/>
PREFIX attributes: <https://rdf.sfia-online.org/9/attributes/>
PREFIX sfia: <https://rdf.sfia-online.org/9/ontology/>
select ?level ?autonomy
where {
skills:DBAD sfia:definedAtLevel/sfia:level ?level.
?level attributes:AUTO ?autonomy.
}
order by ?levelWe can use a small, local LLM for this. We like to use Ollama as a server, and then one of the Mistral or Llama models. The result will be:
Skill Levels Range: 3 to 5
The text requires a minimum level of DBAD_4 because it involves more than just standard
maintenance tasks (DBAD_3) but also configuring tools for automation (DBAD_4), managing
database configuration, and optimizing performance.
Here's the JSON output:
{
"level_required": "DBAD_4",
"skill_relevance": "100%"
}
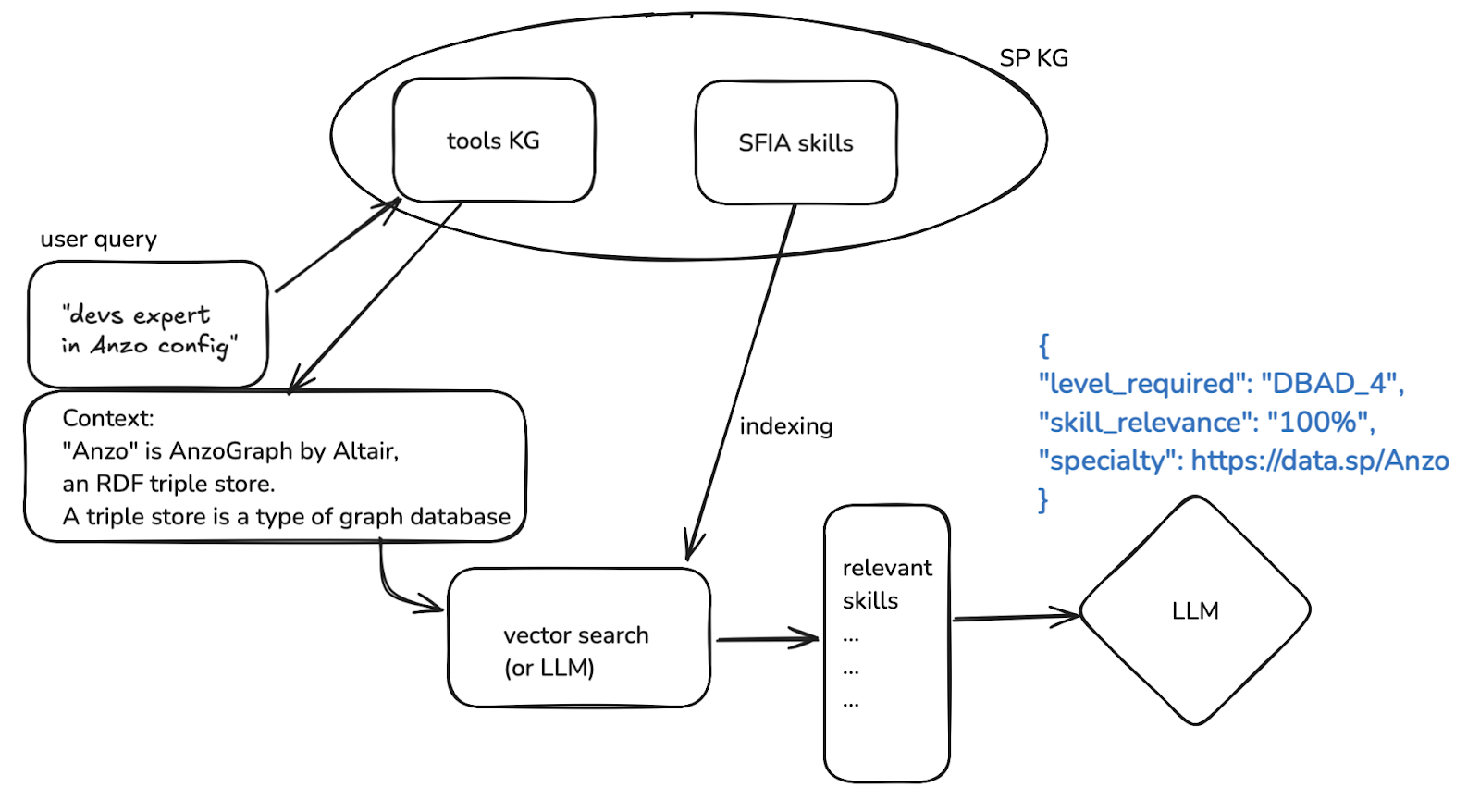
Inference with a KG
Can we show some further level of “intelligence” by adding a Knowledge Graph to our recipe? Suppose we have a Knowledge Graph of tools and technologies. Our intuition is that we should gain the ability to provide some KG context to the LLM, and gain the ability to treat skills’ recommendations for specific technologies.
Let us modify our input to a more specific request – something involving specific domain knowledge – something a generic LLM would not be expert about. Also, something that SFIA does not mention, because it is too specific.
Developers expert in Anzo. They should be able to configure and use Anzo for SHACL validation.
Now, this specific request would be very common at Semantic Partners. This is because we have AnzoGraph (called affectionately “Anzo”) as a partner’s offer. In our KG, Anzo and SHACL are well described. The KG contains the information that Anzo is a (semantic) database, that SHACL is a language to specify constraints on RDF data, and related information. By adding this information to the prompt, we are effectively doing graphRAG, and the LLM will be able to give us again the correct result of DBAD_4 with confidence.
The special thing about doing RAG with a KG (rather than with text documents, or other types of databases) is that it is very easy to request to the graph only the information that is relevant to the query. We have covered this aspect in detail in another SP blog.
Tags
Want to discuss this further?
Start with a 30-minute strategic consultation. We'll assess your data landscape and outline how semantic technology can accelerate your goals.